Prima di tutto occorre distinguere il file XML in due categorie distinte:
- VALID cioè file XML che hanno un DTD (Document Type Definition) che danno una descrizione dei dati contenuti nel file stesso
- WELL-FORMED cioè file XML che non possiedono alcun DTD
Siccome nel primo caso è previsto a priori che i dati assumano una precisa struttura
ad albero e che tale struttura dovrà essere rigorosamente rispettata allora possiamo
pensare di utilizzare il DTD come base della funzione getDescription che mi
ritornerà la cossirpondente struttura in ODLi3.
Nel secondo caso, invece, non essendoci l'obbligo di rispettare nessuna struttura a priori
i dati possono essere disordinati a tal punto da non essere racchiudibili in nessun modo e
tanto meno quindi traducibili in una corrispondente struttura ODLi3
NOTA: il W3C (l'organismo che si occupa di emettere le specifiche ufficiali riguardo al linguaggio XML) pur ammettendo i documenti well-formed ha emesso un documento che raccomanda di inserire sempre il DTD in ogni file creato.
Andiamo ora ad analizzare gli elementi caratteristici di un DTD. Per la descrizione di una struttura di un file XML sono sufficienti (e previsti all'interno di un DTD) 4 markup:
- <!ELEMENT> per la descrizione degli elementi che sono l'elemento fondamentale di un file XML
- <!ATTLIST> per la descrizione degli attributi assegnati ad un elemento
- <!ENTITY> che possono essere di due tipi
- PARSED cioè contenenti dei dati racchiusi da markup e quindi validabili
- UNPARSED conententi altri tipo di dati
- <!NOTATION> che servono per la descrizione del tipo di entità esterna collegata e della eventuale applicazione necessaria per poter visualizzare l'entità stessa.
Per la traduzione della struttura di un file XML è sufficiente solamente l'analisi delle prime 3 strutture (elementi, attributi ed entitità parsed) in quanto il resto si riferisce direttamente ai dati descritti e quindi di competenza del modulo che si occuperà della lettura dei dati.
Algoritmi di traduzione XML-DTD --> ODLi3
Traduzione degli elementi
Questo tipo di traduzione è pressoché automatica in quanto tutte le volte che un elemento è anche nodo dell'albero della struttura (cioè possiede ulteriori elementi figli) possiamo vederlo come una interfaccia di ODLi3. Ad esempio:
<!ELEMENT Fast-Food (name, address, phone?, speciality*, category, nearby?, midprice?, owner?)*>
trova corrispondenza in ODLi3 tramite la sintassi:
interface Fast-Food
(source semistructured Eating_Source)
{
[...]
};
Ogni elemento figlio di un attributo può essere a sua volta padre di altri figli, e quindi essere considerato anch'esso nodo e come tale tradotto con la stessa sintassi appena vista:
<!ELEMENT owner (name, address, job)>
diventa:
interface owner
(source semistructured Eating_Source)
{
[...]
};
Questo mi introduce quindi un nuovo tipo e come tale dovrà essere tradotto nel nodo radice:
interface Fast-Food
(source semistructured Eating_Source)
{
[...]
attribute owner owner*;
[...]
};
Arrivando fino alle foglie per ogni nodo che possono essere tradotto come semplici stringhe e quindi abbiamo:
<!ELEMENT name #PCDATA> <!ELEMENT phone #PCDATA> <!ELEMENT speciality #PCDATA>
che viene tradotto come:
interface Fast-Food
(source semistructured Eating_Source)
{
attribute string name;
[...]
attribute string phone*;
attribute set<string> speciality;
[...]
}
NOTA: allo stato dell'arte attuale non è previsto per i dati XML una differenziazione a seconda dei dati contenuti e quindi possiamo vedere senza nessuna limitazione tutto come una serie di stringhe e come tali tradurle con la relativa sintassi ODLi3.
A questo punto occorre introdurre tutto un discorso sulla opzionalità degli elementi in XML che trovano una corrispondenza in ODLi3 come spiegato in dettaglio nel capitolo 5.3.2 della tesi di Cataldo.
Traduzione degli attributi
Questa struttura non è prevista in ODLi3 e quindi non prevede una traduzione altrettanto automatica come già visto per gli elementi. Peculiarità di un attributo di XML è quello di mantenere una relazione univoca con l'elemento a cui si riferisce e questa caratteristica deve essere ovviamente mantenuta. La scelta che si è fatta è quella di mantenere questa relazione includendo nel nome dell'attributo ODLi3 anche in nome dell'elemento a cui si riferisce e quindi:
<!ELEMENT city #PCDATA> <!ATTLIST city zipcode CDATA>
trova traduzione nella corrispondente sintassi ODLi3:
attribute string city; attribute string city_zipcode;
Nel caso un elemento preveda la presenza di più attributi allora potrebbe essere comodo intrdurre una struttura del tipo:
typedef struct
{
string name;
string value;
} attlist
in cui racchiudere tutte le informazioni. Il che mi tradurre una struttura XML come
<!ELEMENT city (#PCDATA)> <!ATTLIST city zip_code CDATA phone_prefix CDATA>
nella corrispondente sintassi ODLi3
attribute string city; attribute set<attlist> city_attributes;
La sintassi di un attributo XML è ovviamente molto più complesso di quanto brevemente visto in questa pagina e come tale prevede anche delle particolarità nella traduzione. In questa sede possiamo citare la possibilità di avere delle primary key e le relative foreign key all'interno di un file XML (e come tali traducibili in ODLi3) che è una cosa alquanto insolita per una sorgente di dati semistrutturati.
Rimandando al capitolo 5.4 della tesi di Cataldo ed alla relataiva tabella riassuntiva per avere tutti i dettagli riguardante gli algortimi di traduzione degli attributi possiamo soffermarci in questa sede illustrando con brevi esempi la possibilità di creare delle costanti
<!ATTLIST zip_code state CDATA #FIXED "ITALY">
che in ODLi3 diventa
const string state="ITALY";
e di creare dei tipi enumerati
<!ELEMENT recapito (#PCDATA)> <!ATTLIST recapito type (telefono|cellualre|fax|email) 'telefono'>
che trova la corrispondente traduzione ODLi3 nelle righe
enum recapito_type
{
'telefono',
'cellualre',
'fax',
'email'
}
{
attribute string recapito;
attribute string recapito_type;
}
La traduzione delle entità «parsed»
Questo caso è l'unico di interesse per la descrizione della struttura di un file XML, in quanto tutti gli altri, come già detto, sono di competenza del modulo che dovrò occuparsi del trattamento dei dati.
Fermandosi quindi a livello di DTD possiamo avere una struttura, divisa in 3 file separati, del tipo
// catalogo_stellare23.xml
<!DOCTYPE cielo SYSTEM "catalogo_star3.dtd" [ <!ENTITY % STELLA2 SYSTEM "catalogo_star2.dtd" > <!ELEMENT cielo (costellazione*, galassia*)+ > %STELLA2; ]>
[...]
// catalogo_star2.dtd
<!ELEMENT costellazione (stella+, segmento?)*>
<!ELEMENT stella ( coordinate, magnitudine ) > <!ELEMENT coordinate EMPTY > <!ELEMENT magnitudine EMPTY > [...]
// catalogo_star3.dtd
<!ELEMENT segmento EMPTY > <!ELEMENT galassia (#PCDATA) > [...]
Ed una qualsiasi parser risolverebbe questa situazione costruendo un
albero come quello rappresentato in figura 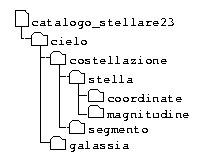
che è quindi visto come un normale albero e come tale potrà essere tradotto con gli algortimi che sono stati illustrati precedentemente.