In questa tabella sono riportati gli algoritmi dettagliati di come andrà a lavorare il Wrapper per la generazione dello schema sorgente in ODLi3 dato un DTD di XML
DTD XML |
Struttura ODLi3 |
<!ELEMENT [name] [list]> |
interface [name]
(source semistructured ...)
{
[...]
}
|
<!ELEMENT [name] (#PCDATA)> |
attribute string [name]; |
<!ELEMENT [name] ANY> |
typedef any
{
string strvalue;
}
attribute string [name]; |
<!ELEMENT [name] EMPTY> |
attribute boolean [name]; |
<!ELEMENT [name] ([l1],...,[ln])> <!ELEMENT [lx] ([sl1],...,[slm])> |
interface name
(source semistructured ...)
{
[...]
attribute [lx] [lx];
[...]
}
interface [lx]
(source semistructured ...)
{
[...]
}
|
<!ELEMENT [name] ([l1],...,[lx]?,...,[ln])> |
attribute string [lx]*; |
<!ELEMENT [name] ([l1],...,[lx]*,...,[ln])> <!ELEMENT [lx] (#PCDATA)> |
attribute set<string> [lx]; |
<!ELEMENT [name] ([l1],...,[lx]+,...,[ln])> <!ELEMENT [lx] (#PCDATA)> |
attribute set<string> [lx]; |
<!ELEMENT [name] (#PCDATA|[other])*> <!ELEMENT [other] ([list])> |
interface [name]
(source semistructured ...)
{
[...]
};
union
{
string
};
|
<!ELEMENT [father] ([childA]|[childB])> <!ELEMENT [childA] #PCDATA> <!ELEMENT [childB] ([list])> |
interface [father]
(source semistructured ...)
{
attribute [father]_union_1
[father]_union_1;
}
typedef [father]_union_1
{
string [childA];
}
union
{
[...]
}
|
<!ELEMENT [name] (#PCDATA)> <!ATTLIST [name] [att1] CDATA [att2] CDATA> |
attribute string [name]; attribute string [name]_[att1]*; attribute string [name]_[att2]*; |
<!ATTLIST [name] [att1] CDATA #REQUIRED> |
attribute string [name]_[att1]; |
<!ATTLIST [name] [att1] CDATA #IMPLIED> |
Questo tipo di attributo ha delle implicanze solamente a
livello di dati e non di struttura e come tale viene considerato come un attributo
"normale'' cioè sarà tradotto comeattribute string [name]_[att1] |
<!ATTLIST [name] [att1] CDATA #FIXED [value]> |
const string [att1] = '[value]'; |
<!ATTLIST [name] [att1] ID #REQUIRED> |
In questo caso è necessario l'intervento del progettista che
indichi se questo attributo debba essere effetivamente considerato come una primary
key oppure nointerface ...
key[name]_[att1]
)
{
attribute string [name]_[att1];
}
Qeusta traduzione è stata possibile dal momento che il progettista ha confermato che si tratta effetivamente di una primary key. |
<!ATTLIST [name] [att1] IDREF #IMPLIED> <!ATTLIST [name] [att1] IDREFS #IMPLIED> |
interface ...
(...
foreign key ([name]_[att1])
references [interface])
{
[...]
attribute string [name]_[att1]
[...]
}
Dove [interface] rappresenta il nome dell'interfaccia ODLi3 a cui il progettista ha indicato che tale foreign key debba referenziare. |
<!ATTLIST [name] [att1] ENTITY> <!ATTLIST [name] [att1] ENTITIES> |
Non necessita di conversione in quanto riguarda esclusivamente i dati. |
<!ATTLIST [name] [att1] NMTOKEN> <!ATTLIST [name] [att1] NMTOKENS> |
Non necessita di conversione in quanto riguarda esclusivamente i dati. |
<!ATTLIST [name] [att1]([l1]|...|[ln]) '[lx]'> |
enum [name][att1]
{
'[l$_1$]'
[...]
'[l$_n$]'
}
[...] attribute [name]_[att1] [name]_[att1]; |
<!ENTITY [name] [unparsed]> |
Non viene tradotta in quanto riguarda esclusivamete i dati. |
<!ENTITY [name] [parsed]> |
Non ha una traduzione diretta in ODLi3, ma il parser deve occuparsi di ricostruire l'eventuale DTD esterno che contiene l'entità e tradurlo con le regole finora illustrate. |
<!NOTATION ...> |
Non ha un corrispondente in ODLi3 in quanto serve esclusivamente per la gestione dei dati in XML. |
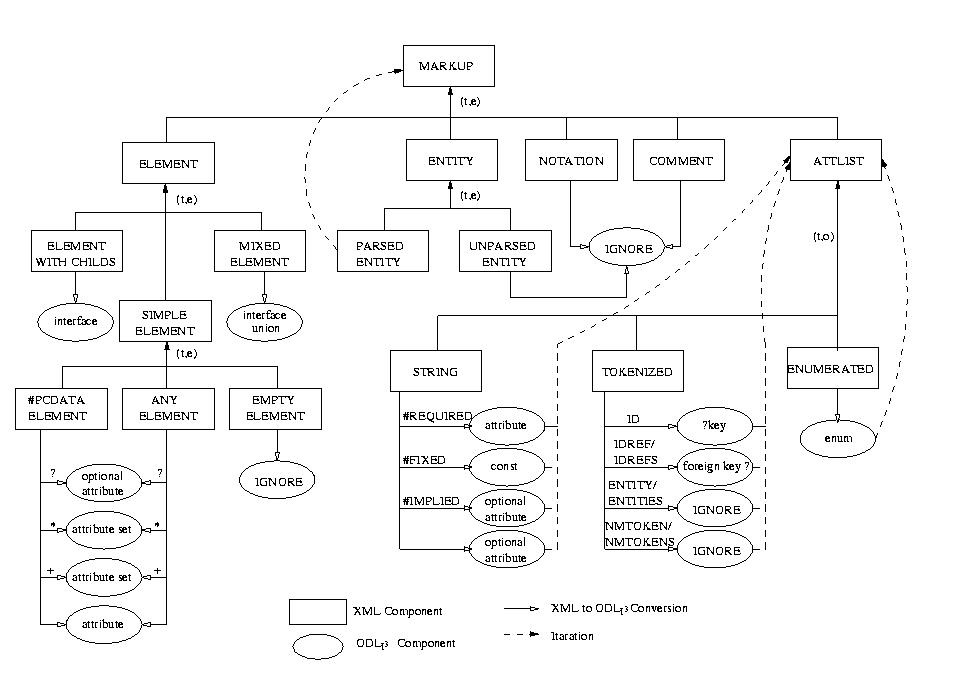
Sulla base di questa tabella si può anche costruire una pseudo schema ER che rappresenta graficamente l'algoritmo di funzionamento del parser.
The MOMIS Home Page
{kind=link}