Un modo di rendere disponibili tali informazioni e di facilitare la loro reperibilità é quello di definire un documento RDF:
ODLI3 é nato come linguaggio per l'integrazione di sorgenti di dati eterogenee, per cui é naturalmente adatto per catturare un certo tipo di conoscenza quale: chiavi, foreign key, regole d'integrità, ecc.. . Volendo garantire il massimo della condivisione di tale conoscenza, dobbiamo muoverci all'interno degli standard che si sono affermati o che si stanno affermando.
A mio avviso la scelta migliore é quella di fare un uso congiunto di XML-Schema ed RDF(S); non menziono volutamente XML1.0 in quanto le difficoltà incontrate da Lenzi nel progetto del traduttore da XML1.0 a ODLI3 testimoniano la non adeguatezza di tale standard per la condivisione di informazioni fortemente tipizzate come sono quelle di una base di dati.
XML-Schema e RDF(S) nascono entrambi per facilitare la condivisione
delle informazioni sul web, ma hanno caratteristiche complementari:
<complexType name="openAttrs">
<annotation>
<documentation xml:lang="en">
This type is extended by almost all schema types
to allow attributes from other namespaces to be
added to user schemas.
</documentation>
</annotation>
<complexContent>
<restriction base="anyType">
<anyAttribute namespace="##other"
processContents="lax"/>
</restriction>
</complexContent>
</complexType>
openAttrs é una restrizione di anyType (la radice della gerarchia dei tipi di dato per uno schema), può avere qualsiasi attributo (anyAttribute) proveniente da qualsiasi namespace (namespace=''\#\#other'') e se il parser non riesce ad ottenere lo schema in cui l'attributo è definito (processContents=''lax'') non segnala errore altrimenti procede alla validazione.
Nel nostro caso possiamo definire uno schema XML-Schema, chiamiamolo meta.xsd d'ora in avanti, in cui definire tutti quegli attributi che permettono di ottenere il collegamento con le definizioni RDF che servono a migliorare la comprensione dello schema che tradurrà le nostre classi ODLI3.
Questo metodo permette di separare la semantica dai vincoli sintattici
e strutturali permettendo di condividere la semantica di diversi schemi
e di promuovere l'interoperabilità semantica.
Un modo di rendere disponibili tali informazioni e di facilitare
la loro reperibilità é quello di definire un
documento RDF:
il collegamento della definizione RDF di un'interfaccia nello schema XML-Schema può avvenire definendo un'attributo interface:
<xsd:attribute name="interface" type="anyURI"/>
interface é definito come attributo di tipo anyURI
ciò indica la possibilità di contenere valori del tipo:
ed utilizzarlo nella traduzione di una interfaccia:
<complexType name="PersonType"
xx:interface="http://a.b.c/interfaces.rdf#Person">
.....
</complexType>
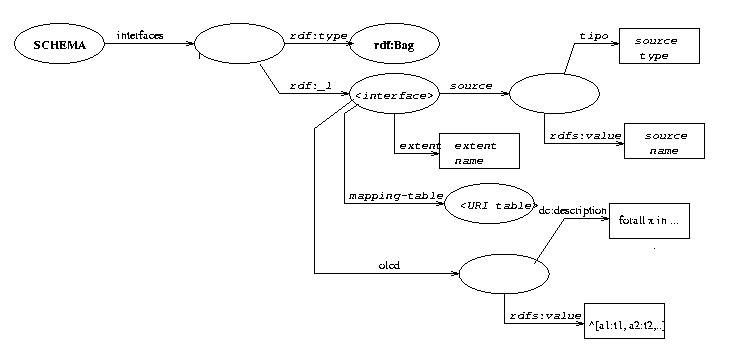
Lo SCHEMA é un'insieme d'interfacce ODLI3
; ogni interfaccia ha le seguenti proprietà:
Il documento RDF ha associato uno schema-RDF che oltre ad elencare le risorse e le proprietà usate nel documento fornisce un aiuto alla leggibilità dello schema XML-Schema di alcuni concetti ODLI3 .
Vorrei spendere qualche parola in più sul concetto di leggibilità; é importante garantire un elevato grado di non ambiguità tra schema ODLI3 e schema XML-Schema per permettere ad eventuali applicazioni in grado di comprendere la logica descrittiva OLCD di poter usufruire al 100% del supporto che questa DL da ad ODLI3.
Vediamo in dettaglio la definizione del documento e dello schema RDF
affrontando la traduzione di concetti ODLI3
interface Professor: Person
{
....
relationship set<Student> advises
inverse Student::advisor;
.....
};
Tale elemento in ODLI3 introduce una corrispondenza binaria fra due risorse che in XML-Schema non è catturata:
<element name="advises">
<complextype>
<sequence>
<element name="Student" type="StudentType"
maxOccurs="unbounded"/>
</sequence>
<attribute name="inverse" type="string" use="fixed"
value="advisor"/>
</complextype>
</element>
La traduzione per l'interfaccia Student è:
<element name="advisor">
<complextype>
<sequence>
<element name="professor" type="ProfessorType"/>
</sequence>
<attribute name="inverse" type="string" use="fixed"
value="advises" />
</complextype>
</element>
introduciamo nell'elemento che traduce il percorso diretto (anche in quello che traduce l'inverso) un'attributo semantica definito di tipo anyURI con il riferimento ad una proprietà RDF che spiega la sua semantica:
<element name="advises" meta:semantica="..../#advises"/>
mentre in RDF-Schema:
<rdf:Property ID="advises">
<rdfs:label xml:lang="eng">advises</rdfs:label>
<rdfs:label xml:lang="it">consiglia</rdf:label>
<rdfs:comment>
Relazione Binaria fra un professore
e l'insieme dei suoi alunni
</rdfs:comment>
<rdfs:comment>
L'inverso è advisor
</rdfs:comment>
<rdfs:seeAlso rdf:resource="#advisor"/>
<rdfs:domain rdf:resource="#Professor"/>
</rdf:Property>
<rdf:Property ID="advisor">
<rdfs:comment>
Relazione fra uno studente e il suo professore
</rdfs:comment>
<rdfs:comment>L'inversa è advises</rdfs:comment>
<rdfs:seeAlso rdf:resource="#advises"/>
<rdfs:domain rdf:resource="#Student"/>
</rdf:Property>
tramite rdfs:seeAlso informiamo che esiste una risorsa che
aiuta a comprendere la definizione della proprietà mentre rdfs:comment
serve per dare una spiegazione human-friendly. Certo non e' che
la situazione sia risolta; ma a mio giudizio e' preferibile all' uso di
attributi o ulteriori elementi nel documento schema XML-Schema, che non
porterebbero ad altro che ad un documento piu' prolisso e meno leggibile.
XML-Schema gestisce l'ereditarietà attraverso l'elemento
<extension
base=".."/> tale meccanismo supporta solo l'ereditarietà singola;
la gestione dell'ereditarietà multipla prevista da ODLI3
comporta una traduzione in XML-Schema che non la evidenzia esplicitamente:
interface Engineer : Person, Graduate
{
.....
}
La traduzione in XML-Schema e':
<complexType name="EngineerType"
meta:interface="interfaces.rdf/#Engineer">
<extension base="Person">
<element ref="Graduate"/>
</complexType>
nello schema XML-Schema con l'attributo meta:interface indichiamo dove si può trovare la definizione della risorsa Engineer con le sue proprietà, tale risorsa può essere definita in RDF-Schema:
<rdfs:Class rdf:ID="Person"/>
<rdfs:Class rdf:ID="Graduate"/>
<rdfs:Class rdf:ID="Engineer">
<rdfs:label>Engineer</rdfs:label>
<rdfs:subclassOf rdf:resource="#Person"/>
<rdfs:subclassOf rdf:resource="#Graduate"/>
</rdfs:Class>
in questo modo é più chiaro, a mio avviso, la relazione
di ereditarietà multipla fra Engineer, Person e Graduate.
Nel complexType che traduce la classe Professor:
<xsd:ComplexType name="ProfessorType"
meta:interface="interfaces.rdf#Professor">
.....
</xsd:ComplexType>
nel documento RDF:
<Professor>
<extent>professors</extent>
...
</Professor>
Nel complexType che traduce la classe Address:
<xsd:ComplexType name="AddressType"
meta:interface="interfaces.rdf#Address">
.....
</xsd:ComplexType>
nel documento RDF:
<Address>
<source
schema:tipo="semistructured"
rdf:value="Eating_Source"/>
...
</Address>
In questo modo un applicazione OLCD-aware e' in grado di capire le limitazioni imposte su una classe ODLI3 le altre applicazioni si dovranno accontentare di una descrizione della regola. Il valore dell attributo dc:description e' stato lasciato vuoto perche' ritengo necessario un intervento del progettista per inserirlo manualmente. il namespace dc si riferisce al vocabolario del Dubline Core Initiative; (dc:description) un'iniziativa nata per facilitare il ritrovamento di risorse elettroniche in un modo simile a quello che si farebbe in una biblioteca.
interface Hospital_Patient
{
attribute long code
mapping_rule ID.Patient.code, ID.Dis_Patient.code;
attribute string name
mapping_rule ( ID.Patient.first_name
and ID.Patient.last_name),
CD.Patient.name;
}
nel documento RDF:
<Hospital_Patient>
<mapping-table rdf:resource="http://a.b.c/Hospital_Table"/>
...
..
.
</Hospital_Patient>
Parser RDF
Nella mia home directory /export/home/marchica
ho installato un parser RDF della ICS-FORTH
(www.ics.forth.gr/proj/isst/RDF/).
E' un parser validante scritto in Java che supporta il
controllo di uno schema. Per provarlo portarsi nella directory RDF_VRP
e lanciare il
comando java VRP.Main <nomefile> [opzioni] alcuni file
di esempio si trovano nella sottodirectory examples. Per maggiori
informazioni leggersi il file README presente nella directory
RDF_VRP. Per un elenco di altri parser RDf vedere l'home page del
working
group su RDF (www.w3.org/RDF).